
Welcome to Part 2 of our comprehensive series on creating a powerful Supply Chain Management App!
In this exciting installment of our series, we continue our journey into the dynamic world of supply chain optimization.
In Part 1, we delved into the realm of data analysis and dashboard creation, laying the groundwork for a robust and efficient supply chain management app.
Now, in Part 2, we shift our focus to the critical aspect of database development. Join us as we explore the intricacies of designing and structuring a database that forms the backbone of your app’s functionality.
Visualizing the Database Structure: A Blueprint for Excellence
Before we delve into the intricacies of database development, let’s take a moment to visualize the database structure that underpins your Supply Chain Management App. The Unified Modeling Language (UML) diagram below provides a clear blueprint of the entities and relationships within your database.
UML Diagram created using PlantUML:
@startuml
!define TABLE customer_id AS INT
!define TABLE order_id AS VARCHAR(50)
entity "customers_df" as customers {
customer_id
customer_name
city
}
entity "products_df" as products {
product_id
product_name
category
}
entity "target_orders_df" as targets {
customer_id
ontime_target%
infull_target%
otif_target%
}
entity "order_lines_df" as order_lines {
order_id
order_placement_date
customer_id
product_id
order_qty
agreed_delivery_date
actual_delivery_date
delivery_qty
In Full
On Time
On Time In Full
}
entity "orders_aggregate_df" as order_aggregate {
order_id
customer_id
order_placement_date
on_time
in_full
otif
}
customers --{ order_lines
order_lines --{ order_aggregate
products --{ order_lines
targets --{ order_lines
@enduml
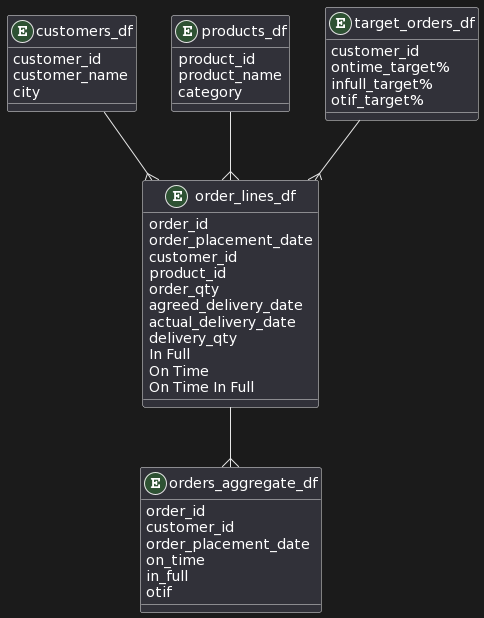
Building the Backbone: Designing Your Database Structure
As you embark on the journey of database development, it’s essential to define a well-structured database schema. The structure of your database will determine how data is organized, stored, and accessed, influencing the overall performance of your supply chain app.
Tables and Relationships: Mimicking Real-World Entities
In the world of supply chain management, various entities such as customers, products, orders, and deliveries play pivotal roles. Each of these entities corresponds to a table in your database. For instance, the Customer entity can be represented by a customers table, while the Product entity maps to a products table.
Establishing relationships between tables is equally important. For instance, the orders table can have foreign key references to the customers and products tables, creating a logical connection between orders, customers, and products.
from sqlalchemy import create_engine, Column, Integer, String, Boolean, Date, Float,ForeignKey
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from config import Config
DATABASE_URI = Config.SQLALCHEMY_DATABASE_URI
engine = create_engine(DATABASE_URI)
Session = sessionmaker(bind=engine)
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customers'
customer_id = Column(Integer, primary_key=True)
customer_name = Column(String)
city = Column(String)
class Product(Base):
__tablename__ = 'products'
product_id = Column(Integer, primary_key=True)
product_name = Column(String)
category = Column(String)
class Target(Base):
__tablename__ = 'targets'
customer_id = Column(Integer, ForeignKey('customers.customer_id'), primary_key=True)
ontime_target_percent = Column(Float)
infull_target_percent = Column(Float)
otif_target_percent = Column(Float)
class OrderLine(Base):
__tablename__ = 'order_lines'
order_id = Column(String(50), primary_key=True)
order_placement_date = Column(Date)
customer_id = Column(Integer, ForeignKey('customers.customer_id'))
product_id = Column(Integer, ForeignKey('products.product_id'))
order_qty = Column(Integer)
agreed_delivery_date = Column(Date)
actual_delivery_date = Column(Date)
delivery_qty = Column(Integer)
in_full = Column(Boolean)
on_time = Column(Boolean)
on_time_in_full = Column(Boolean)
class OrderAggregate(Base):
__tablename__ = 'order_aggregate'
order_id = Column(String(50), primary_key=True)
customer_id = Column(Integer, ForeignKey('customers.customer_id'))
order_placement_date = Column(Date)
on_time = Column(Boolean)
in_full = Column(Boolean)
otif = Column(Boolean)
Crafting Comprehensive Schemas for Seamless Data Interaction
As you delve into the intricate process of designing your database, it’s crucial to anticipate how your application will interact with it. In this regard, schemas play a pivotal role by defining the serialization and deserialization structure, enabling seamless communication between your application and the underlying data. Let’s explore the enhanced schemas that encapsulate the essence of your day-to-day activities.
from marshmallow import Schema, fields
class CustomerSchema(Schema):
customer_id = fields.Integer(dump_only=True)
customer_name = fields.String()
city = fields.String()
class ProductSchema(Schema):
product_id = fields.Integer(dump_only=True)
product_name = fields.String()
category = fields.String()
class TargetSchema(Schema):
customer_id = fields.Integer()
ontime_target_percent = fields.Float()
infull_target_percent = fields.Float()
otif_target_percent = fields.Float()
class OrderLineSchema(Schema):
order_id = fields.String()
order_placement_date = fields.Date()
customer_id = fields.Integer()
product_id = fields.Integer()
order_qty = fields.Integer()
agreed_delivery_date = fields.Date()
actual_delivery_date = fields.Date()
delivery_qty = fields.Integer()
in_full = fields.Boolean()
on_time = fields.Boolean()
on_time_in_full = fields.Boolean()
class OrderAggregateSchema(Schema):
order_id = fields.String()
customer_id = fields.Integer()
order_placement_date = fields.Date()
on_time = fields.Boolean()
in_full = fields.Boolean()
otif = fields.Boolean()
These schemas provide a clear and structured representation of your data entities, making it easier for your application to serialize and deserialize information. Each schema is thoughtfully documented, offering detailed descriptions of the fields to ensure a comprehensive understanding of the data’s purpose.
By employing these schemas, you’re setting the stage for seamless data interaction, enabling your application to efficiently communicate with the database. The robust structure of these schemas ensures that data is accurately captured, processed, and presented within your supply chain management app.
As you continue on your journey towards creating a transformative supply chain management app, these comprehensive schemas will serve as a crucial bridge between your application and the underlying database, fostering a seamless and efficient flow of information.
Configuring Your Application: Setting Up the Database Connection
To facilitate a successful connection between your application and the database, consider the following configuration in your config.py file:
class Config:
SQLALCHEMY_DATABASE_URI = 'sqlite:///mydatabase.db'
SQLALCHEMY_TRACK_MODIFICATIONS = False
Populating Your Database: Data Insertion and Integration To breathe life into your database, you’ll populate it with meaningful data. This involves employing the following steps in your db.py script:
import pandas as pd
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models.DataBase_Models import Base
from schemas.DataBase_Schemas import *
from config import Config
DATABASE_URI = Config.SQLALCHEMY_DATABASE_URI
# Create the engine and session
engine = create_engine(DATABASE_URI)
Session = sessionmaker(bind=engine)
# Create tables in the database
Base.metadata.create_all(engine)
# Load CSV files into DataFrames
customers_df = pd.read_csv('Data/dim_customers_clean.csv')
products_df = pd.read_csv('Data/dim_products_clean.csv')
targets_df = pd.read_csv('Data/dim_targets_orders_clean.csv')
order_lines_df = pd.read_csv('Data/fact_order_lines_clean.csv')
order_aggregate_df = pd.read_csv('Data/fact_orders_aggregate_clean.csv')
# Insert data into the database using SQLAlchemy and Pandas
session = Session()
customers_df.to_sql('customers', con=engine, if_exists='append', index=False)
products_df.to_sql('products', con=engine, if_exists='append', index=False)
targets_df.to_sql('targets', con=engine, if_exists='append', index=False)
order_lines_df = order_lines_df.drop_duplicates(subset=['order_id'])
order_lines_df.to_sql('order_lines', con=engine, if_exists='append', index=False)
order_aggregate_df.to_sql('order_aggregate', con=engine, if_exists='append', index=False)
session.close()
print("Data inserted into the database.")
These steps involve creating the engine and session, generating tables in the database, loading CSV files into DataFrames, and finally, inserting the data into the database using SQLAlchemy and Pandas. Once executed, this script orchestrates the seamless integration of data, bringing your supply chain management app to life.
At this stage your folder structure at this stage should look something like this :
Supply_Chain_Desktop_App/
├── config.py
├── models/
│ ├──__init__.py
│ └── DataBase_Models.py
├── schemas/
│ ├──__init__.py
│ └── DataBase_Schemas.py
├── db.py
├── Tests/
├── original_data/
└── Clean_data/
And there you have it—an intricate exploration of the vital steps involved in crafting a powerful Supply Chain Management App. From visualizing your database’s blueprint to crafting meticulous schemas and seamlessly populating your data, each element we’ve dissected contributes to the grand symphony of supply chain optimization.
As you journey forward, armed with this newfound knowledge, your supply chain management app evolves into a dynamic force, driving efficiency, enhancing decision-making, and propelling your operations toward excellence. Stay tuned for the next chapter in our series, where we’ll unravel the captivating world of application functionality and user experience enhancement.
Are you ready to transform your supply chain management game? Dive in, harness the power of data, and orchestrate the future of supply chain excellence!